Home
Documentation
Publications
Performance
Download
Applications
Simulation
Links
Cyclone Board
LEON/Nios
Acex Board
LEGO MindStorms
Java TCP/IP
Teaching Material
Contact
|
Performance of Various Java Processors
Performance of Various Java Processors
This page contains benchmark results from various embedded Java
systems. If you have access to an embedded Java devices please run
the benchmark
JavaBenchEmbedded
V1.0 and send me your results.
I will include them in the list. Thanks to Philipp Wasmayr the
benchmark is also available as
MIDLet. So feel
free to test your Java enabled mobile phone and drop me a result.
The benchmark framework needs only two system functions: One to
measure time in millisecond resolution and one to print the results.
These functions are encapsulated in LowLevel.java and can be
adapted to environments, where the full Java library is not
available. For example, the leJOS system has very limited output
capabilities and and a special LowLevel.java exists for this
device. The benchmark is straight-forward to use. An example on a
standard JVM is:
javac jbe/DoAll.java
java jbe.DoAll
1 Introduction
Table 1: JOP and various Java processors
|
| Technology | Size | Speed |
| | Logic | Memory | [MHz] |
|
JOP | Altera, Xilinx FPGA | 1830 LCs | 3KB | 100 |
| picoJava | No realization | 128K gates | 38KB | |
| aJile | ASIC 0.25m | 25K gates | 48KB | 100 |
| Moon | Altera FPGA | 3660 LCs | 4KB | |
| Lightfoot | Xilinx FPGA, ASIC | 3400 LCs | 4KB | 40/60 |
| Cjip | ASIC 0.35m | 70K gates | 55KB | 80 |
| Komodo | Xilinx FPGA | 2600 LCs | | 33 |
| FemtoJava | Xilinx FPGA | 2710 LCs | 0.5KB | 56 |
|
|
Table 1 lists the relevant Java processors
available to date. Sun introduced the first version of picoJava
[1] in 1997. Sun's picoJava is the Java processor most
often cited in research papers. It is used as a reference for new
Java processors and as the basis for research into improving various
aspects of a Java processor. Ironically, this processor was never
released as a product by Sun. A redesign followed in 1999, known as
picoJava-II that is now freely available with a rich set of
documentation [2,3].
The architecture of picoJava is a stack-based CISC processor
implementing 341 different instructions and is the most complex Java
processor available. The processor can be implemented
[4] in about 440K gates.
aJile 's JEMCore is a direct-execution Java processor that is
available as both an IP core and a stand alone processor
[5,6]. It is based on the 32-bit JEM2 Java chip
developed by Rockwell-Collins. The processor contains 48KB zero wait
state RAM and peripheral components. 16KB of the RAM is used for the
writable control store. The remaining 32KB is used for storage of
the processor stack.
Vulcan ASIC's Moon processor is an implementation of the JVM to
run in an FPGA. The execution model is the often-used mix of direct,
microcode and trapped execution. As described in [7],
a simple stack folding is implemented in order to reduce five memory
cycles to three for instruction sequences like push-push-add.
The Moon2 processor [8] is available as an encrypted
HDL source for Altera FPGAs or as VHDL or Verilog source code.
The Lightfoot 32-bit core [9] is a hybrid 8/32-bit
processor based on the Harvard architecture. Program memory is 8
bits wide and data memory is 32 bits wide. The core contains a
3-stage pipeline with an integer ALU, a barrel shifter and a 2-bit
multiply step unit. According to DCT, the performance is typically 8
times better than RISC interpreters running at the same clock speed.
The core is provided as an EDIF netlist for dedicated Xilinx devices
and as ASIC.
The Cjip processor [10,11] supports multiple
instruction sets, allowing Java, C, C++ and assembler to coexist.
Internally, the Cjip uses 72 bit wide microcode instructions, to
support the different instruction sets. At its core, Cjip is a
16-bit CISC architecture with on-chip 36KB ROM and 18KB RAM for
fixed and loadable microcode. Another 1KB RAM is used for eight
independent register banks, string buffer and two stack caches. Cjip
is implemented in 0.35-micron technology and can be clocked up to
80MHz. The logic core consumes about 20% of the
1.4-million-transistor chip. The Cjip has 40 program controlled I/O
pins, a high-speed 8 bit I/O bus with hardware DMA and an 8/16 bit
DRAM interface.
Komodo [12] is a multithreaded Java processor with a
four-stage pipeline. It is intended as a basis for research on
real-time scheduling on a multithreaded microcontroller. The unique
feature of Komodo is the instruction fetch unit with four
independent program counters and status flags for four threads. A
priority manager is responsible for hardware real-time scheduling
and can select a new thread after each bytecode instruction.
FemtoJava [13] is a research project to build an
application specific Java processor. The bytecode usage of the
embedded application is analyzed and a customized version of
FemtoJava is generated in order to minimize the resource usage.
FemtoJava is not included in Section 2, as the
processor could not run even the simplest benchmark.
Besides the real Java processors a few FORTH chips (Cjip
[10], PSC1000 [14]) are marketed as Java
processors. Java coprocessors (Jazelle [15], JSTAR
[16]) provide Java execution speedup for general-purpose
processors.
The research project Komodo has now ceased, while FemtoJava is still
being used as a basis for active research. From the
Table 1 we can see that JOP is the
smallest realization of a hardware JVM in an FPGA and also has the
highest clock frequency.
2 Performance
Running benchmarks is problematic, both generally and especially in
the case of embedded systems. The best benchmark would be the
application that is intended to run on the system being tested. To
get comparable results SPEC provides benchmarks for various systems.
However, the one for Java, the SPECjvm98 [17], is
usually too large for embedded systems.
Due to the absence of a standard Java benchmark for embedded
systems, a small benchmark suit that should run on even the smallest
device is provided here. It contains several micro-benchmarks for
evaluating the number of clock cycles for single bytecodes or short
sequences of bytecodes, and two application benchmarks. To provide a
realistic workload for embedded systems, a real-time application was
adapted to create the first application benchmark (Kfl). The
application is taken from one of the nodes of a distributed motor
control system [18]. A simulation of both the
environment (sensors and actors) and the communication system
(commands from the master station) forms part of the benchmark, so
as to simulate the real-world workload. The second application
benchmark is an adaptation of a tiny TCP/IP stack for embedded Java.
This benchmark contains two UDP server/clients, exchanging messages
via a loopback device.
As we will see, there is a great variation in processing power
across different embedded systems. To cater for this variation, all
benchmarks are `self adjusting'. Each benchmark consists of an
aspect that is benchmarked in a loop. The loop count adapts itself
until the benchmark runs for more than a second. The number of
iterations per second is then calculated, which means that higher
values indicate better performance.
All the benchmarks measure how often a function is executed per
second. In the Kfl benchmark, this function contains the main loop
of the application that is executed in a periodic cycle in the
original application. In the benchmark the wait for the next period
is omitted, so that the time measured solely represents execution
time. The UDP benchmark contains the generation of a request,
transmitting it through the UDP/IP stack, generating the answer and
transmitting it back as a benchmark function. The iteration count is
the number of received answers per second.
The following list gives a brief description of the Java systems
that were benchmarked:
- JOP
- is implemented in a Cyclone FPGA, running at 100MHz. The
main memory is a 32-bit SRAM (15ns) with an access time of 2 clock
cycles. The benchmarked configuration of JOP contains a 4KB method
cache [19] organized in 16 blocks. The access to
objects and arrays includes an indirection through a handle in
preparation for the implementation of a real-time garbage collector.
- leJOS
-
As an example for a low-end embedded device we use the RCX robot
controller from the LEGO MindStorms series. It contains a 16-bit
Hitachi H8300 microcontroller [20], running at 16MHz.
leJOS [21] is a tiny interpreting JVM for the RCX.
- KVM
- is a port of the Sun's KVM that is part of the
Connected Limited Device Configuration (CLDC) [22] to Alteras
NIOS II processor on MicroC Linux. NIOS is implemented on a Cyclone
FPGA and clocked with 50MHz. Besides the different clock frequency
this is a good comparison of an interpreting JVM running in the same
FPGA as JOP.
- TINI
- is an enhanced 8051 clone running a software JVM. The
results were taken from a custom board with a 20MHz crystal, and the
chip's PLL is set to a factor of 2.
- Cjip
- The measured system (SNAP) is a replacement of the
TINI board and contains a Cjip clocked with 80MHz and 8MB DRAM.
- muvium
- is a Java batch compiler system for small
microcontroller. The test platform is an 8-bit PIC18F8722 with a
10Mhz internal clock. muvium is not complete Java conform as
e.g. Java int are only 16-bit.
- Komodo
- The benchmark results of Komodo were obtained by Matthias
Pfeffer [23] on a cycle-accurate simulation of Komodo.
- aJ80, aJ100
- aJile's JEMCore is a direct-execution Java processor that is
available in two different versions: the aJ80 and the
aJ100 [5]. A development system, the JStamp
[24], contains the aJ80 with an 8-bit memory, clocked at
74MHz. The SaJe board from Systronix contains an aJ100 that is
clocked with 103MHz and contains 10ns 32-bit SRAM.
- EJC
- The EJC (Embedded Java Controller) platform [25] is a
typical example of a JIT system on a RISC processor. The system is
based on a 32-bit ARM720T processor running at 74MHz. It contains up
to 64 MB SDRAM and up to 16 MB of NOR flash.
- gcj
-
gcj is the GNU compiler for Java. This configuration represents
the batch compiler solution, running on a 266MHz Pentium under
Linux.
- MB
-
MB is the realization of Java on a RISC processor for an FPGA
(Xilinx MicroBlaze [26]). Java is compiled to C with a
Java compiler for real-time systems [27] and the C program
is compiled with the standard GNU toolchain.
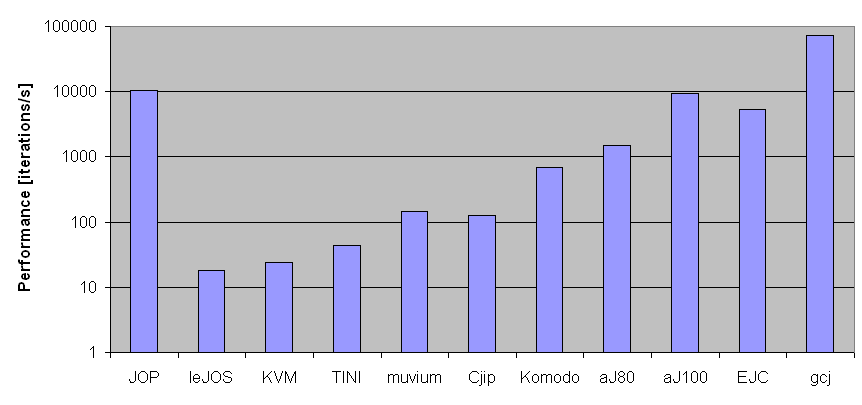
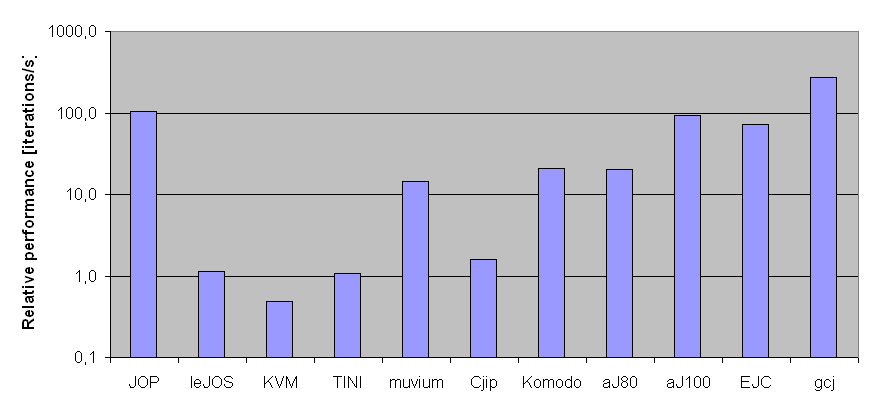 Figure 1: Performance comparison of different Java systems with
application benchmarks. The diagrams show the geometric mean
of the two benchmarks in iterations per second - a higher
value means higher performance. The top diagram shows
absolute performance, while the bottom diagram shows the result
scaled to 1MHz clock frequency.
In Figure 1, the geometric mean of the two
application benchmarks is shown. The unit used for the result is
iterations per second. Note that the vertical axis is logarithmic,
in order to obtain useful figures to show the great variation in
performance. The top diagram shows absolute performance, while the
bottom diagram shows the same results scaled to a 1MHz clock
frequency. The results of the application benchmarks and the
geometric mean are shown in Table 2.
Table 2: Application benchmarks on different Java systems in
iterations per second - a higher
value is better.
Figure 1: Performance comparison of different Java systems with
application benchmarks. The diagrams show the geometric mean
of the two benchmarks in iterations per second - a higher
value means higher performance. The top diagram shows
absolute performance, while the bottom diagram shows the result
scaled to 1MHz clock frequency.
In Figure 1, the geometric mean of the two
application benchmarks is shown. The unit used for the result is
iterations per second. Note that the vertical axis is logarithmic,
in order to obtain useful figures to show the great variation in
performance. The top diagram shows absolute performance, while the
bottom diagram shows the same results scaled to a 1MHz clock
frequency. The results of the application benchmarks and the
geometric mean are shown in Table 2.
Table 2: Application benchmarks on different Java systems in
iterations per second - a higher
value is better.
|
| Frequency | Kfl | UDP/IP
| Geom. Mean | Scaled |
| [MHz] | [Iterations/s] |
|
JOP | 100 | 16,591 | 6,527 | 10,406 | 104.1 |
| leJOS | 16 | 25 | 13 | 18 | 1.1 |
| KVM | 50 | 36 | 16 | 24 | 0.5 |
| TINI | 40 | 64 | 29 | 43 | 1.1 |
| muvium | 10 | 215 | 97 | 144 | 14.4 |
| Cjip | 80 | 176 | 91 | 127 | 1.6 |
| Komodo | 33 | 924 | 520 | 693 | 21.0 |
| aJ80 | 74 | 2,221 | 1,004 | 1,493 | 20.3 |
| aJ100 | 103 | 14,148 | 6,415 | 9,527 | 92.5 |
| EJC | 74 | 9,893 | 2,822 | 5,284 | 71.4 |
| gcj | 266 | 139,884 | 38,460 | 73,348 | 275.7 |
| MB | 100 | 3,792 | | | |
|
|
It should be noted that scaling to a single clock frequency could
prove problematic. The relation between processor clock frequency
and memory access time cannot always be maintained. To give an
example, if we were to increase the results of the 100MHz JOP to
1GHz, this would also involve reducing the memory access time from
15ns to 1.5ns. Processors with 1GHz clock frequency are already
available, but the fastest asynchronous SRAM to date has an access
time of 10ns.
Table 3: Execution time in clock cycles for various JVM bytecodes
|
| JOP | leJOS | KVM | TINI | muvium | Cjip | Komodo | aJ80 | aJ100 |
|
iload iadd | 2 | 836 | 2,197 | 789 | 13 | 55 | 8 | 38 | 8 |
| iinc | 8 | 422 | 2,197 | 388 | 2 | 46 | 4 | 41 | 11 |
| ldc | 9 | 1,340 | 3,296 | 1,128 | 13 | 670 | 40 | 67 | 9 |
| if_icmplt taken | 6 | 1,609 | 3,418 | 1,265 | 42 | 157 | 24 | 42 | 18 |
| if_icmplt n/taken | 6 | 1,520 | 3,296 | 1,211 | 38 | 132 | 24 | 40 | 14 |
| getfield | 22 | 1,879 | 5,738 | 2,398 | 78 | 320 | 48 | 142 | 23 |
| getstatic | 15 | 1,676 | 3,296 | 4,463 | 74 | 3,911 | 80 | 102 | 15 |
| iaload | 37 | 1,082 | 3,052 | 1,543 | 46 | 139 | 28 | 74 | 13 |
| invoke | 133 | 4,759 | 11,231 | 6,495 | 255 | 5,772 | 384 | 349 | 115 |
| invoke static | 100 | 3,875 | 9,278 | 5,869 | 194 | 5,479 | 680 | 271 | 95 |
| invoke interface | 149 | 5,094 | 11,476 | 6,797 | 261 | 5,908 | 1,617 | 531 | 153 |
|
|
2.1 Discussion
When comparing JOP and the aJile processor against leJOS, TINI, and
KVM, we can see that a Java processor is up to 500 times faster than
an interpreting JVM on a standard processor for an embedded system.
The average performance of JOP is even better than a JIT-compiler
solution on an embedded system, as represented by the EJC system.
Even when scaled to the same clock frequency, the compiling JVM on a
PC (gcj) is much faster than either embedded solution. However, the
kernel of the application is smaller than 4KB
[19]. It therefore fits in the level one cache of
the Pentium MMX (16KB + 16KB). For a comparison with a Pentium class
processor we would need a larger application.
JOP is about 7 times faster than the aJ80 Java processor on the
popular JStamp board. However, the aJ80 processor only contains an
8-bit memory interface, and suffers from this bottleneck. The SaJe
system contains the aJ100 with 32-bit, 10ns SRAMs and is a about
10% slower than JOP with its 15ns SRAMs.
The MicroBlaze system is a representation of a Java
batch-compilation system for a RISC processor. MicroBlaze is
configured with the same cache1 as JOP
and clocked at the same frequency. JOP is about four times faster
than this solution, thus showing that native execution of Java
bytecodes is faster than batch-compiled Java on a similar system.
However, the results of the MicroBlaze solution are at a preliminary
stage2, as the
Java2C compiler [27] is still under development.
The micro-benchmarks are intended to give insight into the
implementation of the JVM. In Table 3,
we can see the execution time in clock cycles of various bytecodes.
As almost all bytecodes manipulate the stack, it is not possible to
measure the execution time for a single bytecode. As a minimum
requirement, a second instruction is necessary to reverse the stack
operation. For compiling versions of the JVM, these micro-benchmarks
do not produce useful results. The compiler performs optimizations
that make it impossible to measure execution times at this fine a
granularity.
For JOP we can deduce that the WCET for simple bytecodes is also
the average execution time. We can see that the combination of
iload and iadd executes in two cycles, which means
that each of these two operations is executed in a single cycle. The
iinc bytecode is one of the few instructions that do not
manipulate the stack and can be measured alone. As iinc is
not implemented in hardware, we have a total of 8 cycles that are
executed in microcode. It is fair to assume that this comprises too
great an overhead for an instruction that is found in every
iterative loop with an integer index. However, the decision to
implement this instruction in microcode was derived from the
observation that the dynamic instruction count for iinc is
only 2% [28].
The sequence for the branch benchmark (if_icmplt) contains
the two load instructions that push the arguments onto the stack.
The arguments are then consumed by the branch instruction. This
benchmark verifies that a branch requires a constant four cycles on
JOP, whether it is taken or not.
The Cjip implements the JVM with a stack oriented instruction set.
It is the only example (except JOP) where this instruction set is
documented including the execution time [29]. We
will therefore check some of the results with the numbers provided
in the documentation. The execution time is given in ns, assuming a
66MHz clock. The execution time for the basic integer add operation
is given as 180ns resulting in 12 cycles. The load of a local
variable (when is one of the first four) takes 35 cycles. In the
micro-benchmark we measure 55 cycles instead of the theoretical 47.
We assume that we have to add some cycles for the fetch of the
bytecodes from memory.
During the evaluation of the aJile system, unexpected behavior was
observed. The aJ80 on the JStamp board is clocked at 7.3728MHz and
the internal frequency can be set with a PLL. The aJ80 is rated for
80MHz and the maximum PLL factor that can be used is therefore ten.
Running the benchmarks with different PLL settings gave some strange
results. For example, with a PLL multiplier setting of ten, the aJ80
was about 12.8 times faster! Other PLL factors also resulted in a
greater than linear speedup. The only explanation we could find was
that the internal time, System.currentTimeMillis(), used for
the benchmarks depends on the PLL setting. A comparison with the
wall clock time showed that the internal time of the aJ80 is 23%
faster with a PLL factor of 1 and 2.4% faster with a factor of ten
- a property we would not expect on a processor that is marketed
for real-time systems. The SaJe board can also suffer from the
problem described.
2.2 Execution Time Jitter
For real-time systems, the worst-case of the execution time is of
primary importance. We have measured the execution times of several
iterations of the main function from the Kfl benchmark.
Figure 2 shows the measurements, scaled to
the minimum execution time.
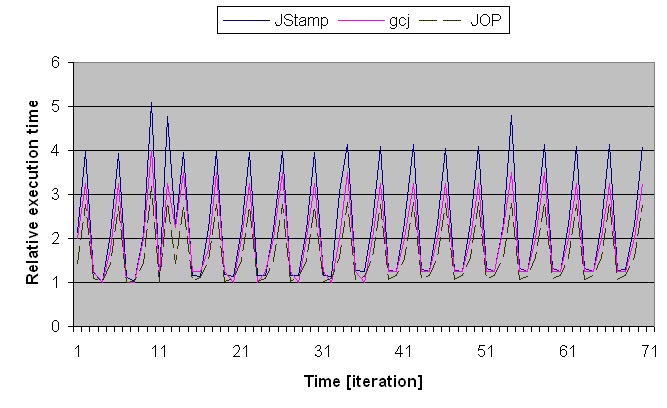
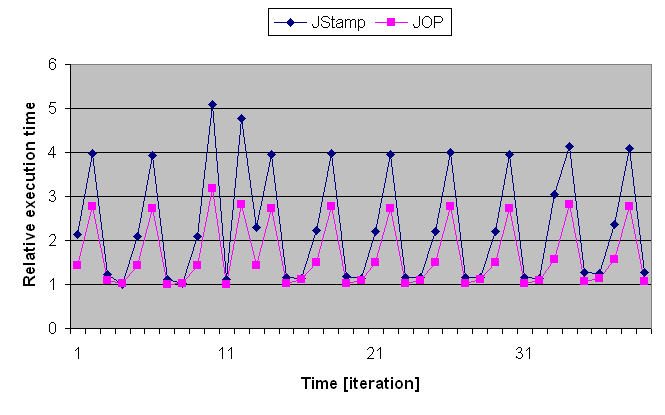 Figure 2: Execution time of the main function for the Kfl benchmark.
The values are scaled to the minimum execution time. The bottom
figure shows a detail of the top figure.
A period of four iterations can be seen. This period results from
simulating the commands from the base station that are executed
every fourth iteration. At iteration 10, a command to start the
motor is issued. We see the resulting rise in execution time at
iteration 12 to process this command. At iteration 54, the
simulation triggers the end sensor and the motor is stopped.
The different execution times in the different modes of the
application are inherent in the design of the simulation. However,
the ratio between the longest and the shortest period is five for
the JStamp, four for the gcj system and only three for JOP.
Therefore, a system with an aJile processor needs to be 1.7 times
faster than JOP in order to provide the same WCET for this
measurement. At iteration 33, we can see a higher execution time for
the JStamp system that is not seen on JOP. This variation at
iteration 33 is not caused by the benchmark.
The execution time under gcj on the Linux system showed some very
high peaks (up to ten times the minimum, not shown in the figures).
This observation was to be expected, as the gcj/Linux system is not
a real-time solution. The Sun JIT-solution was also measured, but is
omitted from the figure. As a result of the invocation of the
compiler at some point during the simulation, the worst-case ratio
between the maximum and minimum execution time was 1313 - showing
that a JIT-compiler is impractical for real-time applications.
It should be noted that execution time measurement is not a safe
method for obtaining WCET estimates. However, in situations where no
WCET analysis tool is available, it can give some insight into the
WCET behavior of different systems.
Figure 2: Execution time of the main function for the Kfl benchmark.
The values are scaled to the minimum execution time. The bottom
figure shows a detail of the top figure.
A period of four iterations can be seen. This period results from
simulating the commands from the base station that are executed
every fourth iteration. At iteration 10, a command to start the
motor is issued. We see the resulting rise in execution time at
iteration 12 to process this command. At iteration 54, the
simulation triggers the end sensor and the motor is stopped.
The different execution times in the different modes of the
application are inherent in the design of the simulation. However,
the ratio between the longest and the shortest period is five for
the JStamp, four for the gcj system and only three for JOP.
Therefore, a system with an aJile processor needs to be 1.7 times
faster than JOP in order to provide the same WCET for this
measurement. At iteration 33, we can see a higher execution time for
the JStamp system that is not seen on JOP. This variation at
iteration 33 is not caused by the benchmark.
The execution time under gcj on the Linux system showed some very
high peaks (up to ten times the minimum, not shown in the figures).
This observation was to be expected, as the gcj/Linux system is not
a real-time solution. The Sun JIT-solution was also measured, but is
omitted from the figure. As a result of the invocation of the
compiler at some point during the simulation, the worst-case ratio
between the maximum and minimum execution time was 1313 - showing
that a JIT-compiler is impractical for real-time applications.
It should be noted that execution time measurement is not a safe
method for obtaining WCET estimates. However, in situations where no
WCET analysis tool is available, it can give some insight into the
WCET behavior of different systems.
3 Resource Usage
Cost, alongside energy consumption, is an important issue for
embedded systems. The cost of a chip is directly related to the die
size (the cost per die is roughly proportional to the square of the
die area [30]). Chips with fewer gates also consume
less energy. Processors for embedded systems are therefore optimized
for minimum chip size.
One major design objective in the development of JOP was to create a
small system that could be implemented in a low-cost FPGA.
Table 4 shows the resource usage for
different configurations of JOP and different soft-core processors
implemented in an Altera EP1C6 FPGA [31]. Estimating
equivalent gate counts for designs in an FPGA is problematic. It is
therefore better to compare the two basic structures, Logic Cells
(LC) and embedded memory blocks.
Table 4: FPGA soft-core processors
|
Processor | Resources | Memory | fmax |
| [LC] | [KB] | [MHz] |
|
JOP Minimal | 1,077 | 3.25 | 98 |
| JOP Basic | 1,452 | 3.25 | 98 |
| JOP Typical | 1,831 | 3.25 | 101 |
| Lightfoot | 3,400 | 4 | 40 |
| NIOS A | 1,828 | 6.2 | 120 |
| NIOS B | 2,923 | 5.5 | 119 |
| SPEAR | 1,700 | 8 | 80 |
|
|
All configurations of JOP contain a memory interface to a 32-bit
static RAM and an 8-bit FLASH for the Java program and the FPGA
configuration data. The minimum configuration implements
multiplication and the shift operations in microcode. In the basic
configuration, these operations are implemented as a sequential
Booth multiplier and a single-cycle barrel shifter. The typical
configuration also contains some useful I/O devices such as an UART
and a timer with interrupt logic for multi-threading. The typical
configuration of JOP needs about 30% of the LCs in a Cyclone EP1C6,
thus leaving enough resources free for application-specific logic.
As a reference, NIOS [32], Altera's popular RISC soft-core,
is also included in the list. NIOS has a 16-bit instruction set, a
5-stage pipeline and can be configured with a 16 or 32-bit datapath.
Version A is the minimum configuration of NIOS. Version B adds an
external memory interface, multiplication support and a timer.
Version A is comparable with the minimal configuration of JOP, and
Version B with its typical configuration.
SPEAR [33] (Scalable Processor for Embedded
Applications in Real-time Environments) is a 16-bit processor with
deterministic execution times. SPEAR contains predicated
instructions to support single-path programming
[34]. SPEAR is included in the list as it is
also a processor designed for real-time systems.
To prove that the VHDL code for JOP is as portable as possible, JOP
was also implemented in a Xilinx Spartan-3 FPGA [35].
Only the instantiation and initialization code for the on-chip
memories is vendor-specific, whilst the rest of the VHDL code can be
shared for the different targets. JOP consumes about the same LC
count (1844 LCs) in the Spartan device, but has a slower clock
frequency (83MHz).
From this comparison we can see that we have achieved our objective
of designing a small processor. The commercial Java processor,
Lightfoot, is 2.3 times larger (and 2.5 times slower) than JOP in
the basic configuration. A typical 32-bit RISC processor consumes
about 1.6 to 1.8 times the resources of JOP. However, the RISC
processor can be clocked 20% faster than JOP in the same
technology. The only processor that is similar in size is SPEAR.
However, while SPEAR is a 16-bit processor, JOP contains a 32-bit
datapath.
Table 5 provides gate count estimates for
JOP, picoJava, the aJile processor, and the Intel Pentium MMX
processor that is used in the benchmarks in the next section.
Equivalent gate count for an LC3 varies between 5.5 and 7.4 - we
chose a factor of 6 gates per LC and 1.5 gates per memory bit for
the estimated gate count for JOP in the table. JOP is listed in the
typical configuration that consumes 1831 LCs. The Pentium MMX
contains 4.5M transistors [37] that are equivalent to
1125K gates.
Table 5: Gate count estimates for various processors
|
Processor | Core | Memory | Sum. |
| [gate] | [gate] | [gate] |
|
JOP | 11K | 40K | 51K |
| picoJava | 128K | 314K | 442K |
| aJile | 25K | 590K | 615K |
| Pentium MMX | | | 1125K |
|
|
We can see from the table that the on-chip memory dominates the
overall gate count of JOP, and to an even greater extent, of the
aJile processor. The aJile processor is about 12 times larger than
JOP.
4 Conclusion
We have seen that JOP is the smallest hardware realization of the
JVM available to date. Due to the efficient implementation of the
stack architecture, JOP is also smaller than a comparable
RISC processor in an FPGA. Implemented in an FPGA, JOP has the
highest clock frequency of all known Java processors.
We compared JOP against several embedded Java systems and, as a
reference, with Java on a standard PC. A Java processor is up to 500
times faster than an interpreting JVM on a standard processor for an
embedded system. JOP is about seven times faster than the aJ80 Java
processor and about 10% faster than the aJ100. Preliminary results
using compiled Java for a RISC processor in an FPGA, with a similar
resource usage and maximum clock frequency to JOP, showed that
native execution of Java bytecodes is faster than compiled Java.
References
- [1]
-
J. M. O'Connor and M. Tremblay, "picoJava-I: The Java virtual machine in
hardware," IEEE Micro, vol. 17, no. 2, pp. 45-53, 1997.
- [2]
-
Sun, picoJava-II Microarchitecture Guide.
Sun Microsystems, March 1999.
- [3]
-
Sun, picoJava-II Programmer's Reference Manual.
Sun Microsystems, March 1999.
- [4]
-
S. Dey, P. Sanchez, D. Panigrahi, L. Chen, C. Taylor, and K. Sekar, "Using a
soft core in a SOC design: Experiences with picoJava," IEEE Design
and Test of Computers, vol. 17, pp. 60-71, July 2000.
- [5]
-
aJile, "aj-100 real-time low power Java processor." preliminary data sheet,
2000.
- [6]
-
D. S. Hardin, "Real-time objects on the bare metal: An efficient hardware
realization of the Javatm virtual machine," in Proceedings of the
Fourth International Symposium on Object-Oriented Real-Time Distributed
Computing, p. 53, IEEE Computer Society, 2001.
- [7]
-
Vulcan, "Moon v1.0." data sheet, January 2000.
- [8]
-
Vulcan, "Moon2 - 32 bit native Java technology-based processor." product
folder, 2003.
- [9]
-
DCT, "Lightfoot 32-bit Java processor core." data sheet, September 2001.
- [10]
-
T. R. Halfhill, "Imsys hedges bets on Java," Microprocessor Report,
August 2000.
- [11]
-
Imsys, "Im1101c (the cjip) technical reference manual / v0.25," 2004.
- [12]
-
J. Kreuzinger, U. Brinkschulte, M. Pfeffer, S. Uhrig, and T. Ungerer,
"Real-time event-handling and scheduling on a multithreaded Java
microcontroller," Microprocessors and Microsystems, vol. 27, no. 1,
pp. 19-31, 2003.
- [13]
-
A. C. Beck and L. Carro, "Low power java processor for embedded
applications," in Proceedings of the 12th IFIP International Conference
on Very Large Scale Integration, December 2003.
- [14]
-
PTSC, "Ignite processor brochure, rev 1.0." Available at http://www.ptsc.com.
- [15]
-
ARM, "Jazelle technology: ARM acceleration technology for the Java
platform." white paper, 2004.
- [16]
-
Nazomi, "JA 108 product brief." Available at http://www.nazomi.com.
- [17]
-
SPEC, "The spec jvm98 benchmark suite." Available at http://www.spec.org/,
August 1998.
- [18]
-
M. Schoeberl, "Using a Java optimized processor in a real world
application," in Proceedings of the First Workshop on Intelligent
Solutions in Embedded Systems (WISES 2003), (Austria, Vienna), pp. 165-176,
June 2003.
- [19]
-
M. Schoeberl, "A time predictable instruction cache for a Java processor,"
in On the Move to Meaningful Internet Systems 2004: Workshop on Java
Technologies for Real-Time and Embedded Systems (JTRES 2004), vol. 3292 of
LNCS, (Agia Napa, Cyprus), pp. 371-382, Springer, October 2004.
- [20]
-
Hitachi, "Hitachi single-chip microcomputer h8/3297 series." Hardware Manual.
- [21]
-
J. Solorzano, "leJOS: Java based os for lego RCX." Available at:
http://lejos.sourceforge.net/.
- [22]
-
Sun, "Java 2 platform, micro edition (j2me)." Available at:
http://java.sun.com/j2me/docs/.
- [23]
-
M. Pfeffer, Ein echtzeitfähiges Java-System für einen
mehrfädigen Java-Mikrocontroller.
PhD thesis, University of Augsburg, 2000.
- [24]
-
Systronix, "Jstamp real-time native Java module." data sheet.
- [25]
-
EJC, "The ejc (embedded java controller) platform." Available at
http://www.embedded-web.com/index.html.
- [26]
-
Xilinx, "Microblaze processor reference guide, edk v6.2 edition." data sheet,
December 2003.
- [27]
-
A. Nilsson, "Compiling java for real-time systems," licentiate thesis, Dept.
of Computer Science, Lund University, May 2004.
- [28]
-
M. Schoeberl, JOP: A Java Optimized Processor for Embedded Real-Time
Systems.
PhD thesis, Vienna University of Technology, 2005.
- [29]
-
Imsys, "ISAJ reference 2.0," January 2001.
- [30]
-
J. Hennessy and D. Patterson, Computer Architecture: A Quantitative
Approach, 3rd ed.
Palo Alto, CA 94303: Morgan Kaufmann Publishers Inc., 2002.
- [31]
-
Altera, "Cyclone FPGA Family Data Sheet, ver. 1.2," April 2003.
- [32]
-
Altera, "Nios soft core embedded processor, ver. 1." data sheet, June 2000.
- [33]
-
M. Delvai, W. Huber, P. Puschner, and A. Steininger, "Processor support for
temporal predictability - the spear design example," in Proceedings of
the 15th Euromicro International Conference on Real-Time Systems, Jul. 2003.
- [34]
-
P. Puschner, "Experiments with wcet-oriented programming and the single-path
architecture," in Proc. 10th IEEE International Workshop on
Object-Oriented Real-Time Dependable Systems, Feb. 2005.
- [35]
-
Xilinx, "Spartan-3 FPGA family: Complete data sheet, ver. 1.2," January
2005.
- [36]
-
M. Schoeberl, "Design and implementation of an efficient stack machine," in
Proceedings of the 12th IEEE Reconfigurable Architecture Workshop
(RAW2005), (Denver, Colorado, USA), IEEE, April 2005.
- [37]
-
M. Eden and M. Kagan, "The pentium processor with mmx technology," in
Proceedings of Compcon '97, pp. 260-262, IEEE Computer Society, 1997.
Footnotes:
1The MicroBlaze with a 8KB
data and 8KB instruction cache is about 1.6 times faster than JOP.
However, a 16KB memory is not available in low-cost FPGAs and is an
unbalanced system with respect to the LC/memory relation.
2As not all language constructs can be compiled, only
the Kfl benchmark was measured. Therefore, the performance bar for
MicroBlaze is missing in Figure 1
3The factors are derived
from the data provided for various processors and from the resource
estimates in [36].
File translated from
TEX
by
TTH,
version 3.67.
On 27 Oct 2006, 17:30.
|