Home
Documentation
Publications
Performance
Download
Applications
Simulation
Links
Cyclone Board
LEON/Nios
Acex Board
LEGO MindStorms
Java TCP/IP
Teaching Material
Contact
Second Approach: More specific for the JVM
The current implementation of the JVM (in JOP1) uses only 63 registers of the
avaliable 1024. The real importend are the sp, pc and vp (pointer to local
variables) of the JVM. The large register file is a real waste in the instruction
set (and of local memory).
Most of the arithmetic instructions are done with arguments on the JVM stack.
So it would be nice if we can do alu operations with a memory operand. But this
counts only, if the memory has no wait states. We can use the internal memory
for the stack with a 'software' cach.
Speeding up JVM execution
The instruction set is changed to do alu operations with (fewer) variables in the local
memory (former registers) and with operands from local memory addressed via
'special' registers (sp, vp).
By squeezing the instruction coding a little bit it is possible to use only
12 bits per instruction.
The iadd looks now:
iadd
ld (sp) // read first argument
add (sp-1) // read second argument
st (sp-1) // store back
ld sp // decrement stack pointer
sub 1
st sp
... // fetch
The execution is reduced to 6 cycles.
If 'special' registers are used they can be
more special. The sp is decremented every ld/alu instruction and incremented every st instruction:
iadd
ld (sp) // read first argument, decrement sp
add (sp) // read second argument, decrement sp
st (sp) // increment sp, store back
... // fetch
This reduces the execution 'stage' of simple JVM instructions to 3 cycles. The minimum of a
one operand/accu design.
Enhancing JVM instruction fetch
Java instructions and data are stored in the same external memory. To enhance the fetch we have to talk about theMemory interface
The current design of JOP uses only 32 bit memory load and store. This makes live easier and fits perfect for the JVM.Almost all JVM operands (except for byte, char and short arrays) are 32 bit. Only JVM instructions are variable length with a lot of single byte.
Fetching 32 bit words for the instructions and shifting them in software to use the data for 1 to 4 JVM instructions is too expensive. Using a dedicated hardware for prefetching the instructions mixed with memory access from the cpu (ld, st) is complex.
The external memory for the current test board is a single byte SRAM. The memory interface serializes the 32 bit access. One read/write takes 4*3+2 cycles. Using a single SRAM is a cheap solution for an embedded system and the SRAM is 'relativ' fast compared to the slow clock for the FPGA. This relation of CPU speed to RAM access time also reflects the factor for fast CPUs with 32/64 bit dynamic RAM.
Taking this factor into account we can decide to move the entire memory interface out of the CPU core. The external memory can only be accessed via 'special' registers. This means:
- no memory access via ld/alu/st
- no wait states for ld/alu/st (simpler cpu core)
- memory access in 'background' (early read, delayed write)
- slower access if waiting for the read (polling in sw)
- more instructions for memory access
ld (sp) // get address
st mem_rd_addr // memio register, start read
... // do some stuff
loop
ld mem_rd_rdy
bz loop // is memory ready?
ld mem_rd_data // read data
Fetch and Decode
Moving the JVM pc to the memory interface with prefetch and auto increment the iadd witch fetch is reduced to:
iadd
ld (sp)
add (sp)
st (sp)
ld jvm_instr // 'special' register
ld (a) // load address from jump table accu indirect
jp (a) // jump accu indirect to instruction
This version of iadd takes 5 + 3 cycles without wait for memory.
Moving the lookup in the jump table to the hardware saves one more cycle. If the memory interface
is not ready it will simple deliver a NOP JVM instruction.
If Interrupts are pending the memory interface will send the address of the ISR. This makes interrupt handling transparent for the JOP core.
The next step is to add a 'special' jump instruction. This instruction moves the new address direct to the JOP pc:
iadd
ld (sp)
add (sp)
st (sp)
jinstr // the 'special' jp
Now an iadd takes 3 + 3 cycles. Knowing the most time in advance when to jump to the next execution
block it's possible to code the jump 3 cycles earlier with a normal instruction:
iadd
ld (sp), jinstr // 'jump' in 3 cycles
add (sp)
st (sp)
Now fetch and decode run concurrent to the JOP core and take no cycles.
But this means one bit in the instruction set in every instruction for this jump. It is also possible to move the length of the JVM instruction (in cycles) to the jump table. So the JVM fetch logic knows when to deliver a new jump address.
The overall pipeline now contains 5 stages:
- byte code fetch
- byte code decode
- jop instruction fetch
- jop instruction decode/operand read
- jop instruction execute
Instruction Set
Removing the displacement in the address the instruction set can be reduced to 8 bit.The instruction set of the current JOP2 implementation:
| 000c aaaa | ld mem |
| 001c aaaa | and mem |
| 010c aaaa | or mem |
| 011c aaaa | xor mem |
| 100c aaaa | add mem |
| 1010 aaaa | st mem |
| 1011 oooo | bz $+2+off |
| 1100 oooo | bnz $+2+off |
| 1101 pppp | ld periph |
| 1110 pppp | st periph |
| 1111 0000 | ld (sp) |
| 1111 0001 | and (sp) |
| 1111 0010 | or (sp) |
| 1111 0011 | xor (sp) |
| 1111 0100 | ld (a) |
| 1111 0101 | ld sp |
| 1111 0110 | ldc |
| 1111 0111 | add (sp) |
| 1111 1000 | st sp |
| 1111 1001 | st ar |
| 1111 1010 | st (sp) |
| 1111 1011 | st (ar) |
| 1111 1100 | jp |
| 1111 1101 | shr |
| 1111 1110 | jbc |
| 1111 1111 | nop |
Diagrams
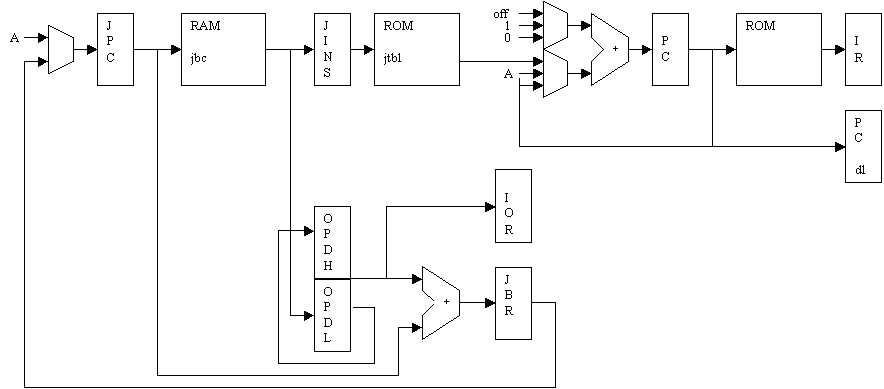
Java and JOP fetch
Decode and execute
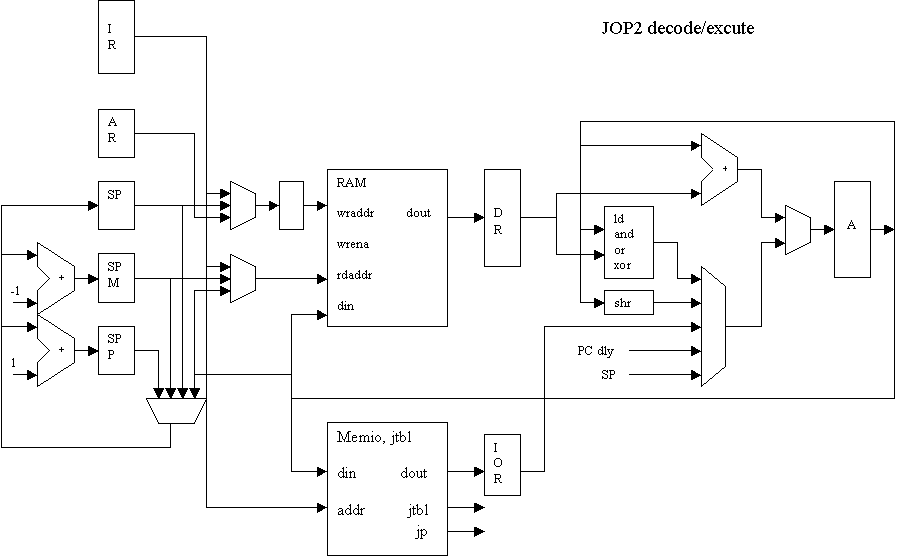
Further enhancement can be achived by trying to execute basic JVM instructions in one cycle. This lends to the next redesign:
Third Approach: A stack machine